Development / Search Architecture
Data flow
Indexing
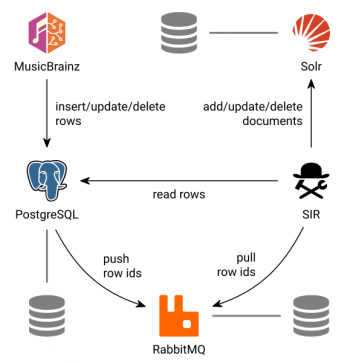
- When MusicBrainz updates its database,
- PostgreSQL triggers queue reindex messages;
- These are pulled from RabbitMQ by SIR,
- which then gathers data to be indexed from the database,
- and finally builds searchable documents and sends these to the Solr search server.
Searching
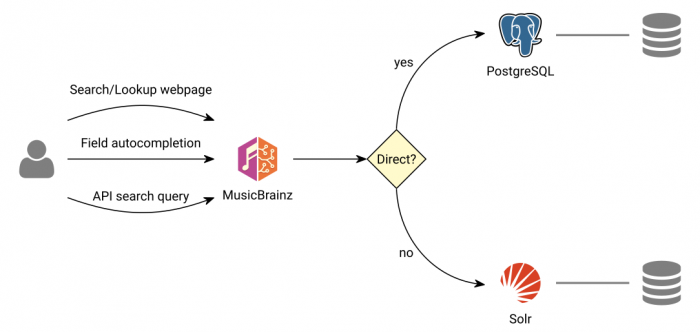
Search can be accessed either by website visitors, or by editors, or by users of MusicBrainz API clients such as MusicBrainz Picard:
- Search webpage (GET at https://musicbrainz.org/search):
- Search form (POST to
musicbrainz.org/search?query=…):
This form is usually accessed from the search field in website top navigation bar. - Tag lookup form (POST to
musicbrainz.org/taglookup?…):
This form is available from the above Search webpage but makes more specific queries.
It is the target form of “Lookup in Browser” feature in MusicBrainz Picard. - Other lookup forms (POST to
musicbrainz.org/otherlookup/…?…):
This form is available from the above Search webpage and allows to make simple queries from identifiers only (barcode, IPI, MBID…).
- Search form (POST to
- Field completion (POST to
musicbrainz.org/ws/js/…?query=…):
Fields that match MusicBrainz entities (for example, the area of an artist)
have an autocompletion feature which is making search queries behind the scene. - API search query (POST to
musicbrainz.org/ws/2/…?query=…):
This kind of query is made by API clients such as MusicBrainz Picard.
See “MusicBrainz_API/Search” for client developer documentation.
There are three search modes:
- Direct database search: This is the legacy mode to search the database directly using PostgreSQL. It is currently kept as a fallback when indexed search is not working. It has limited capabilities (no searchable field, name search only, etc.).
- Indexed search: This is the simplest plain search mode, using Solr. It searches through both accented and unaccented names, aliases, and more. See
request-params.xmlfiles in mbsssss repository.
- Advanced indexed search: This is the most versatile search mode, using Solr. It allows to search through specific fields using the Lucene query syntax. See
schema.xmlfiles in mbsssss repository. See also “Indexed_Search_Syntax” for user documentation.
These modes are used or are made available as follows:
| Search access | Direct database search | (Simple) Indexed search | Advanced indexed search |
|---|---|---|---|
| Search form | Yes | Yes (default) | Yes |
| Tag lookup form | No | No | Yes (limited) |
| Other lookup form | Yes (limited) | No | Yes (limited) |
| Field autocompletion | Yes | Yes (default) | No |
| API search query | No | Yes | Yes (default) |
Searching from MusicBrainz mirror without local Solr server
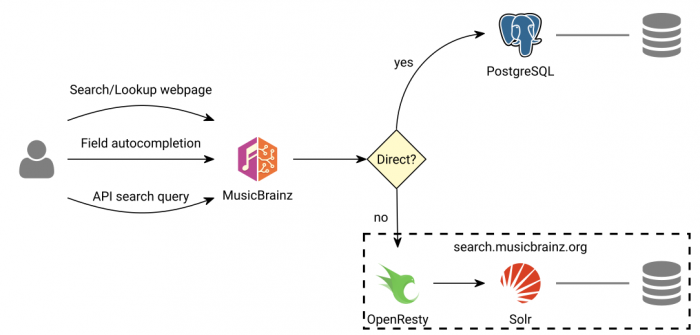
MusicBrainz mirrors can be set up with or without local Solr server, for a matter of resources consumption. When they run their own local Solr server, search works as described in the above section. When they do not run their own local Solr server, they rely on remote calls to search.musicbrainz.org instead.
Components
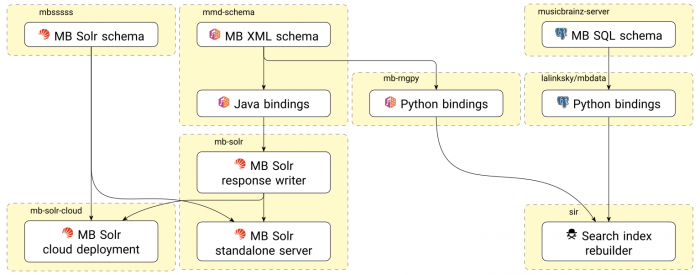
Services explained in the above section about data flows are composed of many components maintained across different repositories.
Here is a complete list of components with their repositories used to make indexed search to work:
- MusicBrainz database schema: See
admin/sql/directory in musicbrainz-server repository.
It defines how data is stored in PostgreSQL by MusicBrainz Server.- Python bindings for the above MB DB schema: See SQLAlchemy Models in lalinsky/mbdata repository.
- MusicBrainz XML metadata schema: See
schema/directory in mmd-schema repository.
It defines data returned by MusicBrainz API which is handled by MusicBrainz Server for lookup and browse queries, and by Solr search server for search queries.- Java bindings for the above MB RELAX NG schema: See
brainz-mmd2-jaxb/directory in the same mmd-schema repository. - Python bindings for the above MB RELAX NG schema: See Python package in distinct mb-rngpy repository.
- Java bindings for the above MB RELAX NG schema: See
- MusicBrainz Solr search schema: See cores defined in mbsssss repository.
It mainly defines how searchable documents are structured and searched, that is mostly everything about searchable fields. - MusicBrainz Solr query response writer: See
mb-solrdirectory in mb-solr repository.
It defines how search results are formatted, using the Java bindings for the above MB RELAX NG schema. - MusicBrainz Solr standalone server: See
Dockerfilefile in the same mb-solr repository. - MusicBrainz Solr cloud deployment: See deployment scripts in private mb-solr-cloud repository.
- Search index rebuilder (SIR): See sir repository and sir documentation.
It uses both Python bindings above: the one for the above MB DB schema and the other for the above MB RELAX NG schema.
It also usespysolrto communicate with Solr server and must comply with MusicBrainz Solr search schema.
Updates
Given the above components and their relationships both at build time and at run time, updating one of these components may affect others, more particularly when it comes to:
- External dependencies that must be compatible across components: Solr/pysolr, Java, Python…
- Internal interfaces used to communicate between components: query parameters to Solr search server…
- Data schemas which have specific policies about breaking changes:
- Database schema: It is the most stable and can be either:
- - extended without breaking change through
ACTIVE_DATABASE_SCHEMAin production, changes must remain optional for mirrors.- - updated (with or without breaking change) through schema change releases for mirrors, once every six months at most.
- Web API schema: It is very stable too but can be either:
- - extended without breaking change at any time,
- - completely reworked through web service major versions, once every few years at most.
- Search schema: There has been no breaking change since it has been released and deployed on mirrors. To be noted:
- - request parameters used for simple indexed search can be easily changed at any time,
- - new searchable fields can be added at any time, but it requires rebuilding the corresponding index to be useful,
- - existing searchable fields can be modified or deleted, but it probably requires a special announcement with upgrade notes for mirrors.
- - new searchable fields can be added at any time, but it requires rebuilding the corresponding index to be useful,
To make smoother updates, it can be useful to have compatibility code in MusicBrainz Server to work with any version of search components.
Latest update that involved all of the three above-mentioned schemas: Adding first release date to recordings; See MBS-1424 and SEARCH-218 for linked code changes.